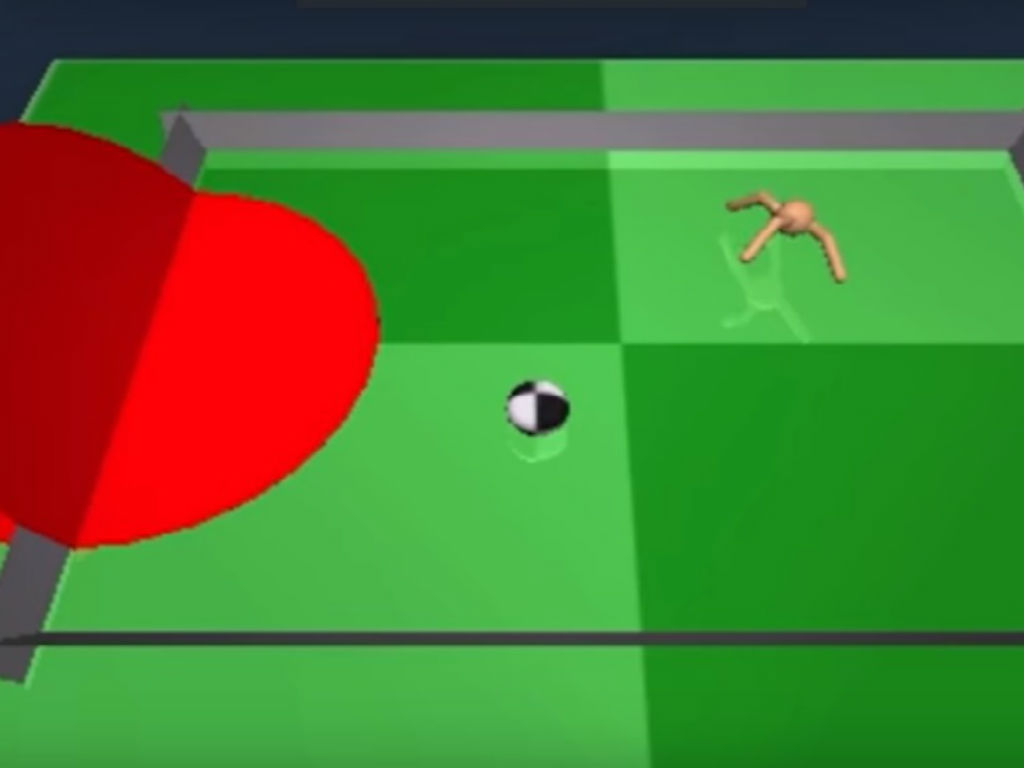
DeepMind, el laboratorio de inteligencia artificial de Google, presentó el pasado viernes 17 de junio una actualización de sus más recientes logros en aprendizaje de máquinas. Dentro de los avances de AI de Google está un experimento en el que lograron entrenar a una hormiga virtual para que juegue fútbol, según informó VentureBeat.
Mediante una publicación en el blog del laboratorio, David Silver explicó los más recientes avances de la tecnología de AI de Google, dentro de los que está un algoritmo avanzado que permite a una hormiga virtual jugar fútbol sin ningún conocimiento previo del deporte.
DeepMind usa un sistema llamado ‘aprendizaje de reforzamiento’ (RL) que consiste en aprender por prueba y error a través de recompensas o castigos. Junto a RL también se usa ‘deep learning’, que consiste en entrenar redes neuronales artificiales con mucha información para que luego el sistema haga inferencias propias y produzca nueva información.
Con RL, y sus evoluciones, Google ha logrado que sus agentes jueguen videojuegos con la misma capacidad de un humano y sin necesidad de entrenarlos en las dinámicas de los juegos, sino en habilidades de solución de problemas y de recibir recompensas.
Google ha logrado que sus máquinas jueguen igual que un humano e incluso son capaces de ganarles en juegos de estrategia. Google tiene un programa llamado AlphaGo, con el que se le enseñó a un agente de AI a jugar un juego llamado ‘Go’, un juego chino antiguo parecido al ajedrez. Hace unos meses Google enfrentó a AlphaGo con el mejor jugador de ‘Go’ del mundo, Lee Se-dol y le ganó. El sistema mezcla una red neuronal y un árbol de decisión para saber cómo moverse en el juego. Pero antes el programa había analizado las partidas de los mejores jugadores del mundo para aprender a jugar.
Para entender mejor cómo hace esta hormiga deportista, es necesario hacer un pequeño repaso de lo que ha hecho hasta el momento Google en AI.
Aprender a comportarse
Los agentes de AI de DeepMind deben realizar juicios constantemente para seleccionar buenas acciones sobre las incorrectas. Ese conocimiento se representa a través de un algoritmo llamado ‘Q-network’ que estima la recompensa total que un agente espera recibir luego de ejecutar una acción determinada. Hace dos años el laboratorio presentó el primero de estos algoritmos de RL. La idea era combinar los algoritmos de ‘Q-network’ con redes neuronales artificiales. Las redes neuronales artificiales son sistemas que simulan la forma en que funcionan las neuronas de los seres vivos. Los intentos anteriores de combinar estos dos sistemas presentaron algunos inconvenientes, como aprendizaje inconstante. Para solucionar estas inestabilidades, los algoritmos ‘Deep Q-Networks’ de Google (DQN) almacena todas las experiencias de entrenamiento del agente de AI y después toma muestras al azar de ellas. Luego las reproduce de forma aleatoria para que el agente obtenga información diversa de entrenamiento.
La ‘máquina’ gana
Luego de hacer este entrenamiento, Google aplicó el DQN para que el agente aprendiera a jugar videojuegos en la consola Atari 2600. El sistema observa los pixeles que componen el juego en la pantalla, luego correlaciona esa información con los datos que previos de la recompensa que le genera cierto puntaje adquirido dentro del juego. A partir de esa correlación selecciona qué hacer en el videojuego. A través de un reporte, Google demostró que pudo entrenar varios agentes con DQN para que jugaran 50 juegos diferentes sin tener ningún conocimiento previo del juego como tal. Incluso el sistema logró un desempeño parecido al de un humano en casi la mitad de los juegos.Con estos algoritmos Google construyó un sistema masivo de RL que llamaron Gorila, que usa la plataforma de Google Cloud para acelerar el tiempo de entrenamiento de los agentes de AI. Gorila se ha aplicado a algunos sistemas dentro de Google.
‘Multitasking’ en su máxima expresión
Google no se conformó con Gorila para seguir desarrollando su método de aprendizaje por recompensas. Así que recientemente presentó otro método que es más práctico y efectivo basados en órdenes asincrónicas de RL. La idea es que el agente de AI pueda ejecutar varias acciones en pararelo. Esto provee una alternativa para que los agentes solucionen mejor los problemas que se presentan en videojuegos. El algoritmo asincrónicas, llamado A3C, combina algunos algoritmos de ‘Q-network’ con la tecnología de ‘deep learning’ para seleccionar las mejores acciones, es decir las que le den mejores recompensas al agente. La diferencia es que necesita muy poco tiempo de entrenamiento, comparado con DQN, y muchos menos recursos de energía de los que usa Gorila. Con A3C Google lanzó Labyrinth, una suite de navegación en 3D de laberintos y juegos de rompecabezas. Los agentes son capaces de resolver estos juegos con la mismo rendimiento que un humano. El mismo algoritmo de Labyrinth le permite a la hormiga meter goles sin necesidad de haber entrenado al agente para jugar fútbol. El agente solo necesita saber qué acciones le darán más recompensas. Para eso, el agente también crea un sistema de estrategias que le permiten ejecutar varias acciones al tiempo, y junto a una estrategia de prioridades dentro del juego, la hormiga no falla ningún tiro al arco.
Imagen: captura de pantalla.
















